My passion for science goes to physics in general. I am endlessly fascinated by the ability of physics to let us understand why the world works in such crazy ways and how humans influence it and are influenced by it. Such is also the the case for traffic, where drivers control their individual vehicles in cooperation and sometimes in competition with each other. I am sure you have been stuck in traffic many times, and if you are the inquisitive type, you have probably also wondered why congestion happens out of nowhere? Here’s your explanation, and I hope you will find it interesting, if you do not know it already.
Instability
You are driving happily along the freeway. Traffic is flowing well but gradually getting denser. As more and more cars get to share the space on the road, traffic slows but continues to flow steadily. At some point you start getting the eerie feeling that danger is lurking. Up ahead, you see brake lights switching on briefly here and there, and you suspect that traffic is close to congestion, so you also shift your foot back and forth between the accelerator and the brake pedal.
When it happens, it comes out of nowhere. Suddenly traffic comes to an abrupt stop. Nothing seems to have caused the event. Traffic just stopped for no obvious reason. The rest of the way to your destination is a frustrating sequence of slow starts and sudden stops. Why does this happen and why can’t the idiots in the other cars just keep going without stopping all the time for no reason? Why does traffic become unstable?
It is not that difficult to work out, actually. It’s a game of space.
The space of a car
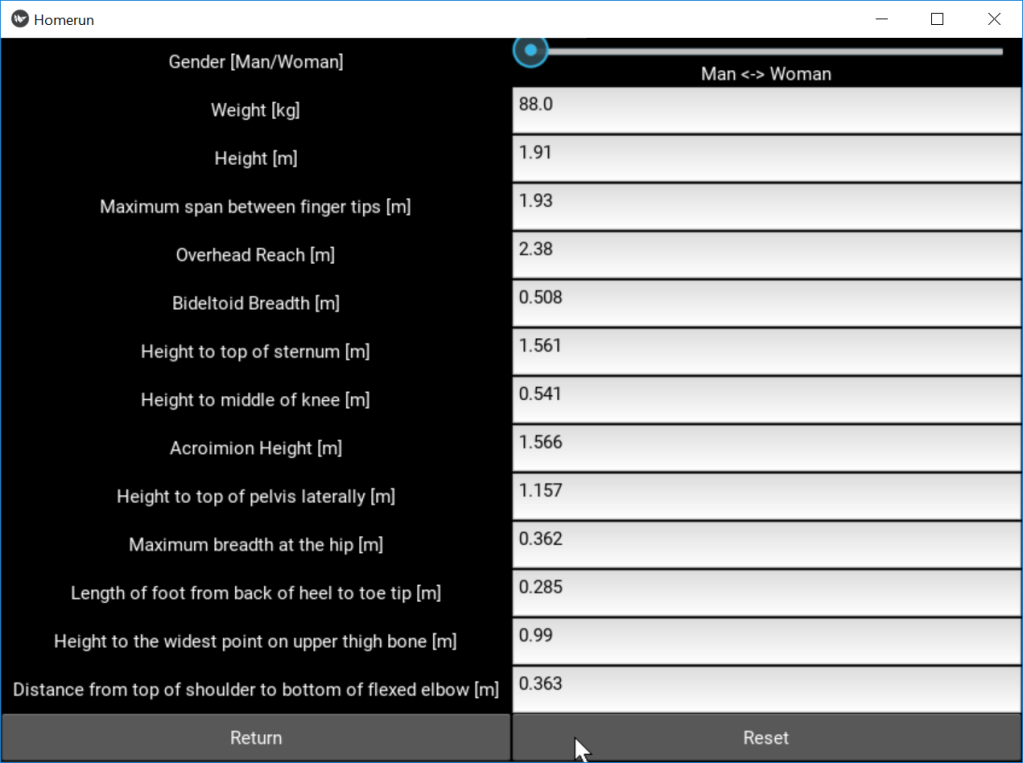
To make things simpler, let us assume the road populated by similar cars that drive at equal distances from each other.
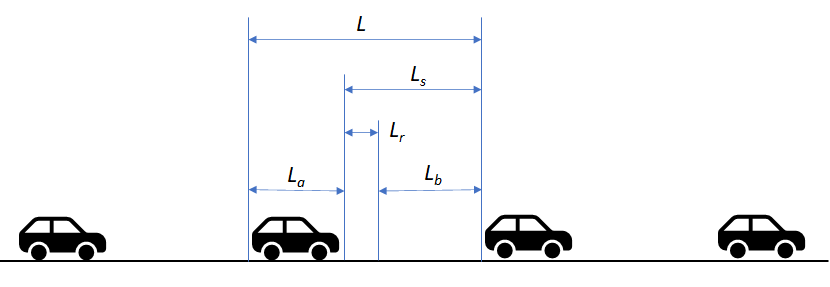
We assume that each car on the road occupies a distance L. This is composed by the length of the automobile, La, plus the distance to the car ahead, Ls. Here, subscript s means “stop” because you learn at the driving academy that this distance should under no circumstances be smaller than the distance required to stop the car from its current speed, lest you may torpedo the car in front of you. If you went to a good driving academy, they also told you that Ls can be decomposed into the sum of Lr and Lb, where the former is the “reaction” distance traveled by the car while you move your foot from the accelerator to the brake, and the latter is the “brake” distance required to bring the car to a halt, after the brake has been activated. From this, we can express L as:
L = La + Lr + Lb
La is just a constant, the length of the car. During the reaction time, tr, the car moves at constant velocity, so we can express the reaction distance as
Lr = trv
The braking distance is a bit more complicated, because it depends on the square of the velocity, i.e. twice the velocity requires four times the braking distance:
Lb = v2/(2a)
where a is the deceleration when braking. This turns out to be the reason for the unstable behavior of traffic, but we will get back to that. For now, let us just notice that higher velocity requires disproportionately more distance to the car in front of you. If you are a decent driver, you know this by instinct.
Flow
Roads are in the business of letting traffic flow from one place to another. The capacity of a road is the amount of traffic is can convey per time, for instance number of cars per hour. This flow capacity, Q, is simple to compute, if we assume that traffic is moving at the velocity v.
Q = v/L
But because L depends on v, the flow capacity depends on velocity in a more complicated way than it appears from the formula above. In fact, it looks like this:
Q = v/[La + trv + v2/(2a)]
It’s time to insert some real numbers. Let us assume that the cars are on the average La = 4m in length. The assumed reaction time depends much on the driver’s age and condition, but it is frequently assumed to be tr = 2 seconds, which seems like much but takes into account that it includes the time taken by the brain to process the situation and decide what to do. The acceleration depends on the tires, the road and the weather conditions, but a reasonable estimate is a = 5m/s2. With this, we can ask: How does the road capacity depend on the velocity of the traffic? Would the road not be able to carry more traffic if people drove faster? Well, here’s your answer:
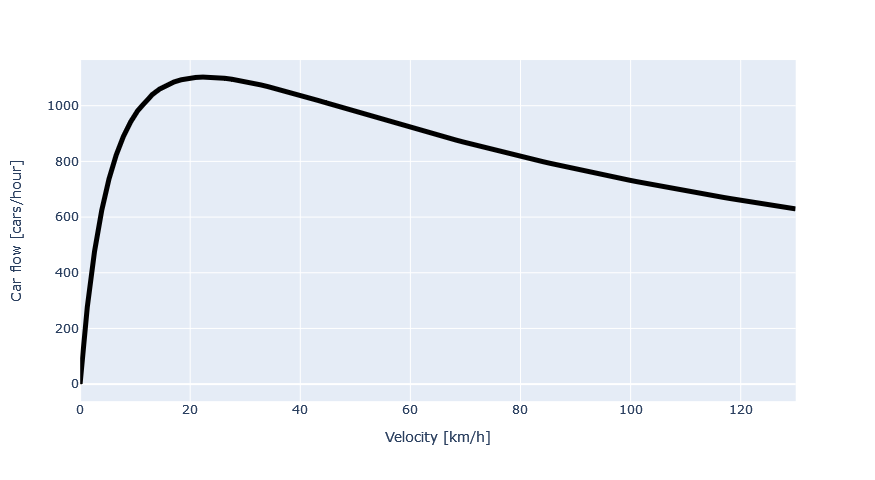
It is not surprising that the flow capacity is zero when the velocity is zero, i.e. traffic does not move at all. When we start the traffic, the flow increases, but it comes to a surprising maximum of 1,102 cars/h at the gentle speed of 23 km/h for the parameter assumptions we have here. The problem is that the necessary distance to the car ahead increases much with the velocity, so the space requirement of each car on the road quickly overtakes the advantage of higher velocity and reduces the flow capacity.
Congestion
Actually, we already have our explanation for the congestion problem: Let us imagine that traffic is flowing at 100 km/h with a low density when more cars enter the freeway from the ramps. The road can accommodate the increased traffic by reducing the speed until we reach a flow of 1,102 cars/h at the speed of 23 km/h. At this point, traffic is locked to this particular speed. Any lower or higher speed will make it impossible to accommodate the traffic that is already on the road, so small perturbations cause nervous drivers to touch the brakes, and the entry of a single additional car from a ramp, in theory, will mean that the problem no longer has a mathematical solution: traffic has no other option than to stop completely. Roads simply have a maximum capacity of cars beyond which traffic can barely flow at all. This is also the reason why it can be so hard to get traffic flowing again after it has stopped.
Disclaimer
Please do not take the numbers in this blog as guidelines for when traffic is safe. Traffic is never safe. The model here is much simplified compared with real traffic, which has vehicles of different lengths and braking abilities and varying road conditions. The best you can do is to maintain a safe speed and distance to the vehicle in front of you. If you feel yourself getting nervous, then you are too close. If you are close and not getting nervous, then you need to brush up on your understanding of physics.